




The Variational Autoencoder (VAE) is a paragon for neural networks that try to learn the shape of the input space. Once trained, the model can be used to generate new samples from the input space.
If we have labels for our input data, it’s also possible to condition the generation process on the label. In the MNIST case, it means we can specify which digit we want to generate an image for.
Let’s take it one step further… Could we condition the generation process on the digit without using labels at all? Could we achieve the same results using an unsupervised approach?
If we wanted to rely on labels, we could do something embarrassingly simple. We could train 10 independent VAE models, each using images of a single digit.
That would obviously work, but you’re using the labels. That’s cheating!
OK, let’s not use them at all. Let’s train our 10 models, and just, well, have a look with our eyes on each image before passing it to the appropriate model.
Hey, you’re cheating again! While you don’t use the labels per se, you do look at the images in order to route them to the appropriate model.
Fine… If instead of doing the routing ourselves we let another model learn the routing, that wouldn’t be cheating at all, would it?
Right! 🙂
We can use an architecture of 11 modules as follows:
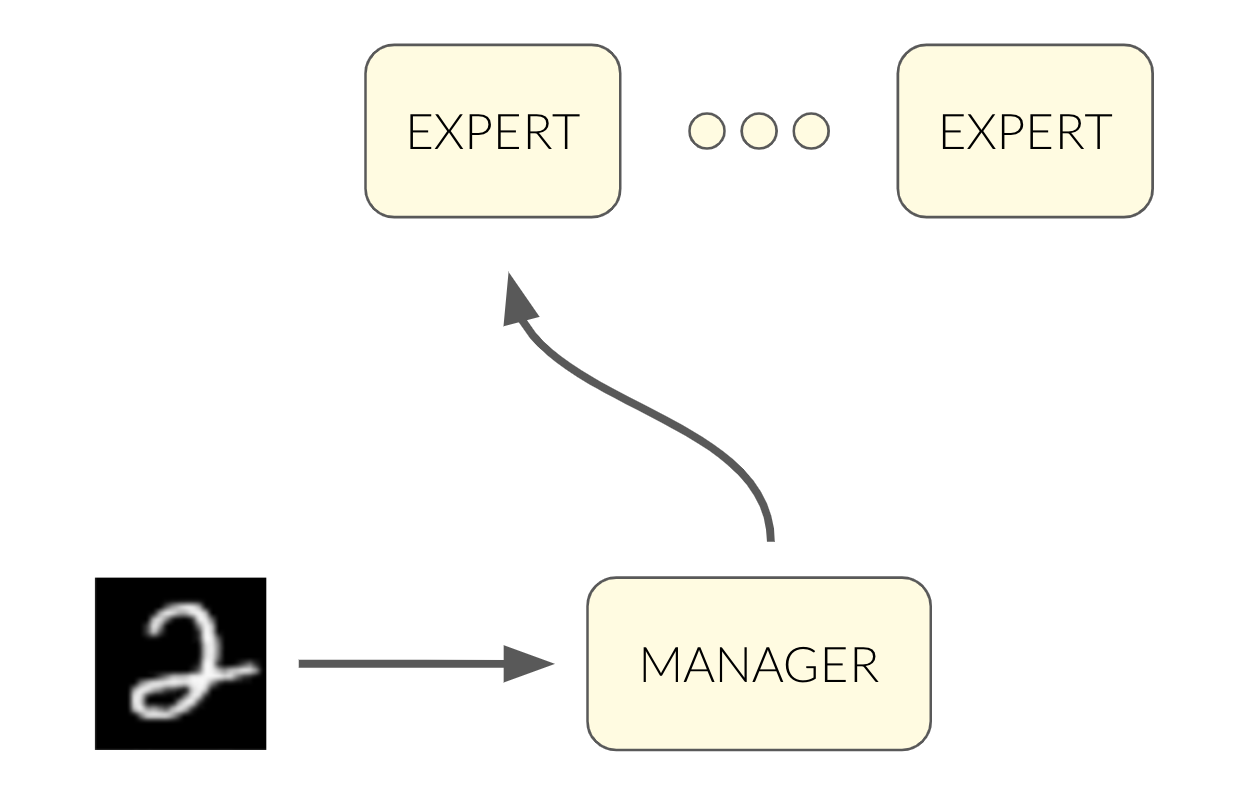
But how will the manager decide which expert to pass the image to? We could train it to predict the digit of the image, but again – we don’t want to use the labels!
Phew… I thought you’re gonna cheat…
So how can we train the manager without using the labels? It reminds me of a different type of model – Mixture of Experts (MoE). Let me take a small detour to explain how MoE works. We’ll need it, since it’s going to be a key component of our solution.
Mixture of Experts explained to non-experts¶
MoE is a supervised learning framework. You can find a great explanation by Geoffrey Hinton on Coursera and on YouTube. MoE relies on the possibility that the input might be segmented according to the $x \rightarrow y$ mapping. Have a look at this simple function:
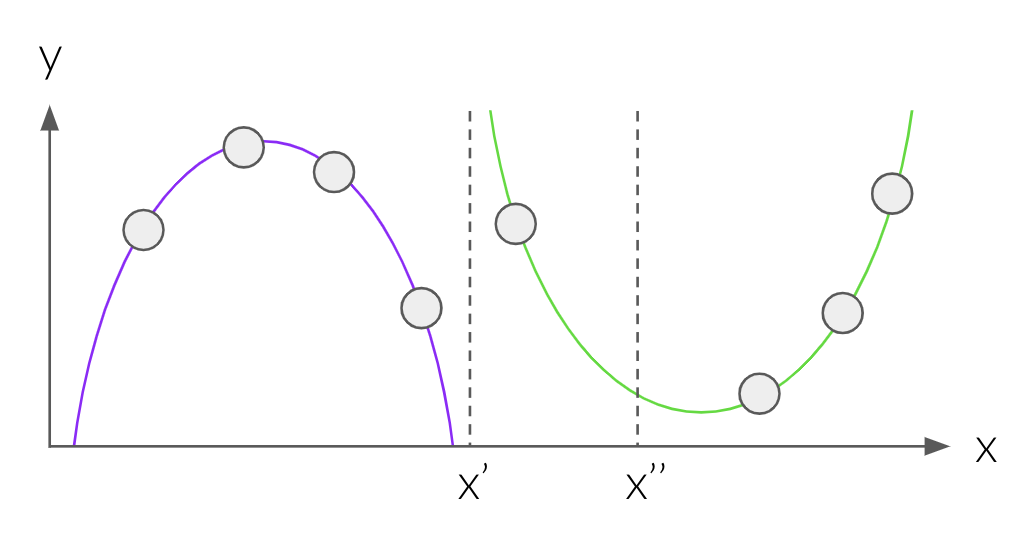
The ground truth is defined to be the purple parabola for $x < x$’, and the green parabola for $x >= x$’. If we were to specify by hand where the split point $x$’ is, we could learn the mapping in each input segment independently using two separate models.
In complex datasets we might not know the split points. One (bad) solution is to segment the input space by clustering the $x$’s using K-means. In the two parabolas example, we’ll end up with $x$” as the split point between two clusters. Thus, when we’ll train the model on the $x < x$” segment, it’ll be inaccurate.
So how can we train a model that learns the split points while at the same time learns the mapping that defines the split points?
MoE does so using an architecture of multiple subnetworks – one manager and multiple experts:
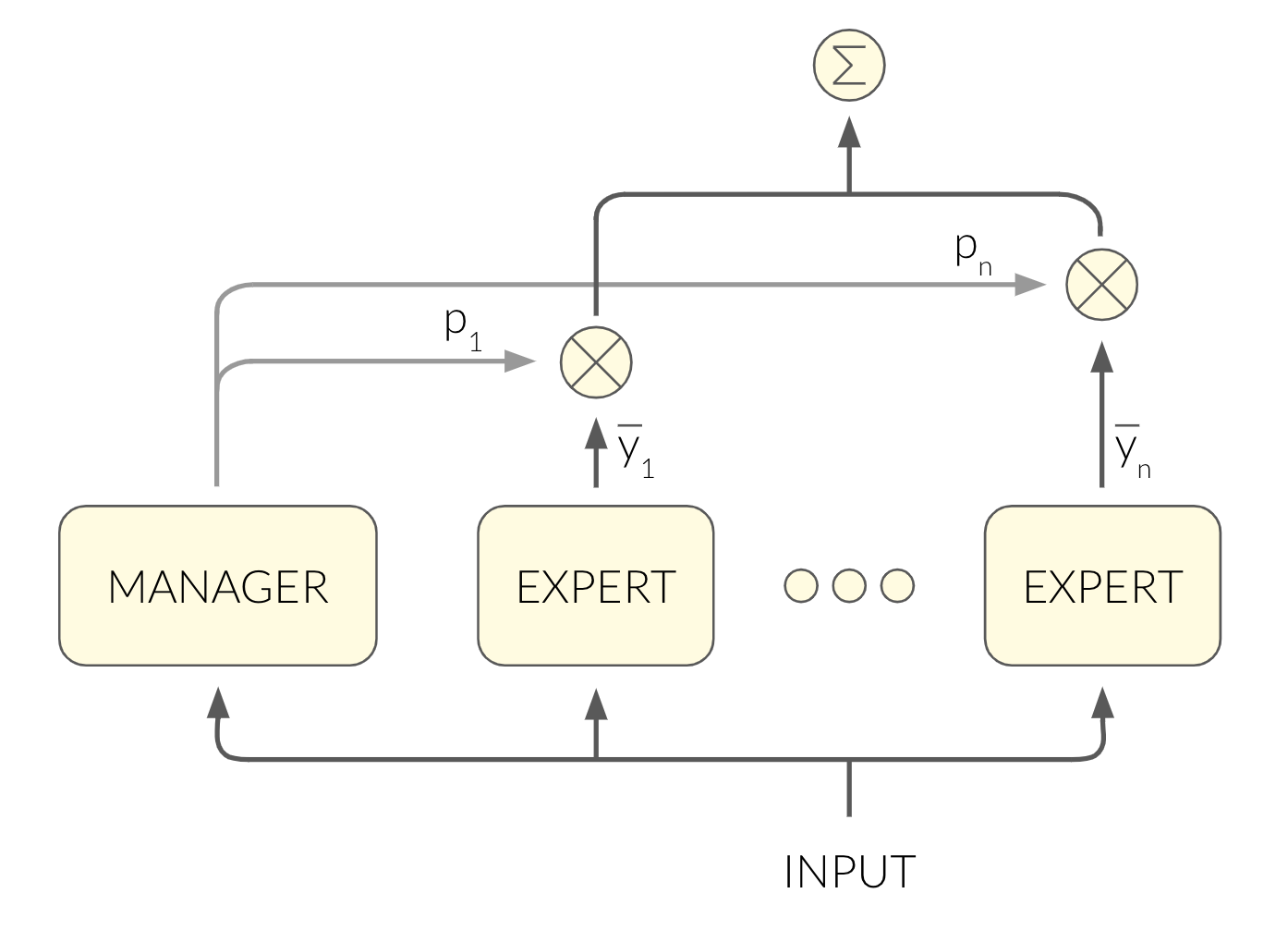
The manager maps the input into a soft decision over the experts, which is used in two contexts:
- The output of the network is a weighted average of the experts’ outputs, where the weights are the manager’s output.
-
The loss function is $\sum_i p_i(y – \bar{y_i})^2$. $y$ is the label, $\bar{y_i}$ is the output of the i’th expert, $p_i$ is the i’th entry of the manager’s output. When you differentiate the loss, you get these results (I encourage you to watch the video for more details):
- The manager decides for each expert how much it contributes to the loss. In other words, the manager chooses which experts should tune their weights according to their error.
-
The manager tunes the probabilities it outputs in such a way that the experts that got it right will get higher probabilities than those that didn’t.
This loss function encourages the experts to specialize in different kinds of inputs.
The last piece of the puzzle… is $x$¶
Let’s get back to our challenge! MoE is a framework for supervised learning. Surely we can change $y$ to be $x$ for the unsupervised case, right? MoE’s power stems from the fact that each expert specializes in a different segment of the input space with a unique mapping $x \rightarrow y$. If we use the mapping $x \rightarrow x$, each expert will specialize in a different segment of the input space with unique patterns in the input itself.
We’ll use VAEs as the experts. Part of the VAE’s loss is the reconstruction loss, where the VAE tries to reconstruct the original input image $x$:
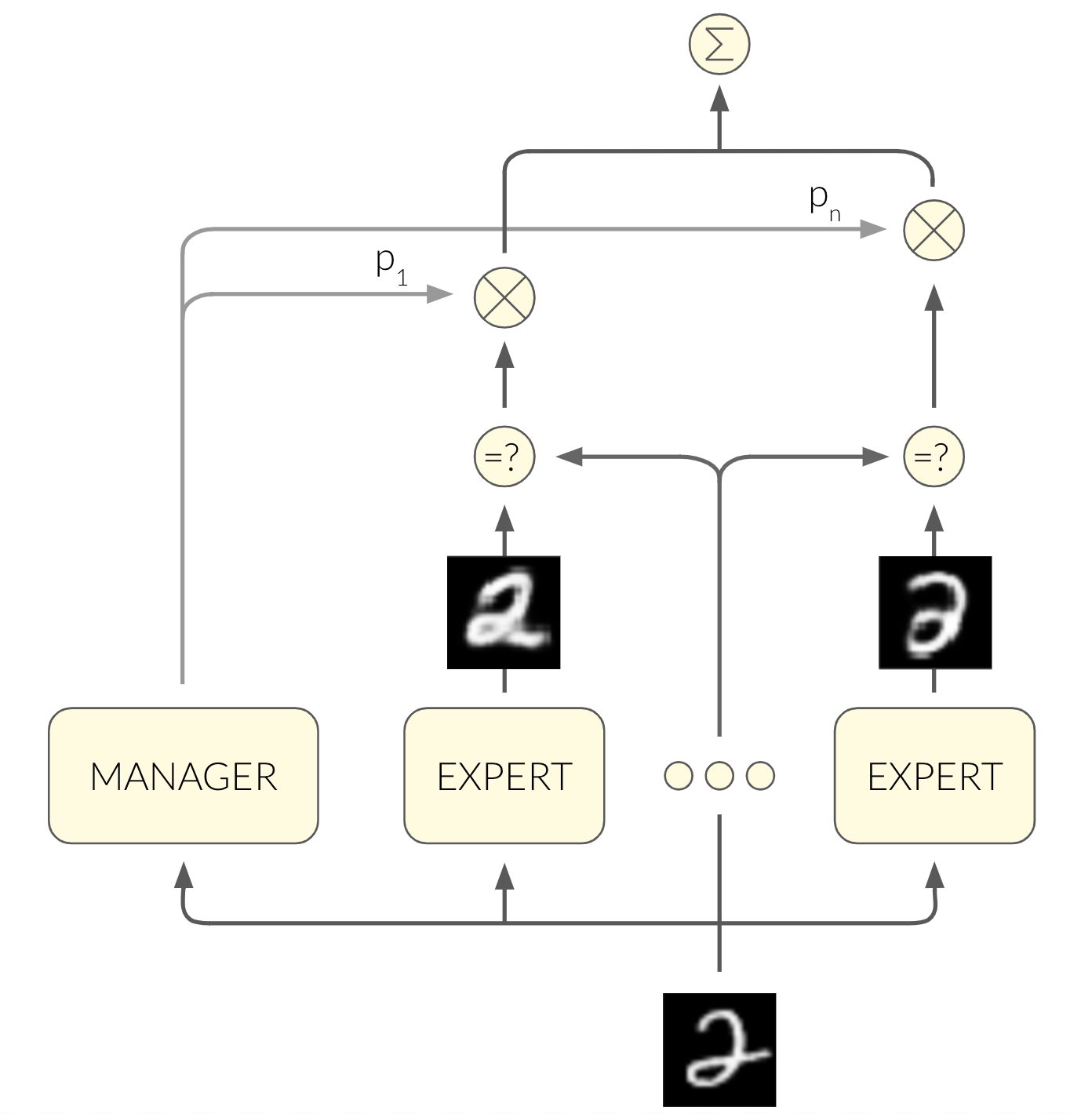
A cool byproduct of this architecture is that the manager can classify the digit found in an image using its output vector!
One thing we need to be careful about when training this model is that the manager could easily degenerate into outputting a constant vector – regardless of the input in hand. This results in one VAE specialized in all digits, and nine VAEs specialized in nothing. One way to mitigate it, which is described in the MoE paper, is to add a balancing term to the loss. It encourages the outputs of the manager over a batch of inputs to be balanced: $\sum_\text{examples in batch} \vec{p} \approx Uniform$.
Enough talking – It’s training time!





